Although we have not officially announced any specific plan, it’s not a secret that at Sequent we’re developing our 2nd generation secure voting platform, because we work out there in the open.

The bulletin board and its requirements
Although we have not officially announced any specific plan, it’s not a secret that at Sequent we’re developing our 2nd generation secure voting platform, because we work out there in the open.
One of the most critical pieces of our 2nd-gen platform will be the bulletin board. In voting systems’ jargon, the bulletin board is a broadcast channel with memory that stores relevant election information such as cast votes, public keys and election results.
What follows is a non-exhaustive list of the requirements we have for the bulletin board:
- Verifiability: It is tamper-evident append-only log. Added entries cannot be removed or modified, and this should be verifiable by third parties for transparency.
- Authenticity: All posts to the bulletin board must be authenticated, in this case with digital signatures.
- Performance: It supports adding multi-gigabyte entries. Intermediate steps of the mixnet cryptographic protocol might include millions of votes. That’s gigabytes worth of data.
- Performance: scales to +1K votes/second. A must for elections with hundreds of thousands or millions of voters. We want to store votes in the board while people are voting, to increase verifiability.
- Storage: Board can be archived/retrieved as files. We want to be able to persist data easily using AWS S3 or similar. A board client should be able to use this bulletin board in read-only mode without having any other backend service running. Anyone should also be able to download easily the board a local copy and work transparently from it.
- Compliance: Supports filtering entry data for compliance reasons like the right to be forgotten in GDPR without compromising other requirements, in particular the verifiability of the tamper-evident log.
- Language: Rust development – it’s the language we have chosen for our 2nd-gen platform.
This is a hard nut to crack with conflicting requirements. That’s one of the wonderful aspects of voting technology: working in challenging problems.
We could debate what is the right technology to implement a bulletin board. There are different approaches others have tried, ranging from trying to use Ethereum or any other blockchain, using git as a simple and well-known hash-chain or perhaps using a database like PostgreSQL as the backend storage. None of those provide a satisfactory level of compliance with the requirements previously outlined. That might be the topic of some other post.
We settled to use a serverless Google Trillian-based log. Which brings us to..
What is Google Trillian?
Long story short, Trillian is a tamper-evident log. Its github repository description is “A transparent, highly scalable and cryptographically verifiable data store.” Trillian is written in Go Language, and it allows to register entries in a log that other can query, monitor and request inclusion of new entries. It’s transparent and tamper-evident because it stores the log using a Merkle Tree, which is just a tree of hashes of data where the leaves are the entries, and it allows to efficiently add entries, verify entries order and inclusion, and compare an evolving tree of entries and see that two different tree snapshots are consistent, i.e. older entries are still there in the expected location.
Google developed Trillian as a generic implementation of Certificate Transparency (CT). If you are reading this blog post, you are using Certificate Transparency. Your web browser and millions of other web browsers use CT to verify that the digital certificate of any website using https have been logged in a publicly available and verifiable trillian-based log. The idea is that the browser will only accept certificates that everyone knows about because they are publicly logged. CT has 8.4B certificates logged so far. And counting. Cool technology indeed.
As mentioned earlier, Google Trillian is just the generic implementation of CT, allowing to log any kind of entries, not just digital certificates. In our case, we will log election data.
Trillian serverless
We cannot use Google Trillian simply as a service, because it doesn’t comply with our requirements: it’s not performant enough either in the size of entries (doesn’t support multi-gigabyte entries) not in terms of speed (with MySQL it handles ~10-20 new entries per second). Also, the storage backend is typically mysql and to access the data, you need the trillian service running.
We’ll be using trillian serverless instead. Instead of using Trillian as a service, we would be using some of the Trillian library code to create our own log. Trillian Serverless (TS) stores everything as files, and any client can just access the log this way – no need for a running backend server, other than a generic file server like AWS S3 or even Github Pages. Each entry will be stored as a file along with a set of tiles that represents the hash tree (Merkle Tree) of the log. Entries can easily be sized in gigabytes, and well, for small entries it’s performant enough as we will see.
A small note about compliance and the right to be forgotten: if for any reason a specific entry needs to be password-protected or just not publicly available anymore, having a hash tree (Merkle Tree) with entries being the leaves of that tree and represented as files allows for checking consistency of the log, even inclusion of a specific entry, even when a specific entry data file is not publicly available anymore. This feature is not implemented yet though.
C FFI, the gold standard in interoperability
At this point we know that we are implementing our Bulletin Board using Rust, but we will be calling a library written in Go. Rust has different kind of data structures than Go. Even though both are compiled and feature strong typing, Go uses a Garbage Collector for dynamically allocating and managing the lifetime of objects in the heap, while Rust uses ownership, the type system and the borrow checker instead. Is this even.. possible?
Turns out it is. The reason is both can talk to each other using a common lower denominator: the C Foreign Function Interface (FFI), which is (excerpt from Wikipedia): “A mechanism by which a program written in one programming language can call routines or make use of services written in another.”
What we intend to do is to end up with a compiled binary, which is our bulletin board service implemented in Rust, that will include a statically linked Go library that provides a C-FFI interface. The binary will depend on little more than libc.
For implementation purposes, we will be needing to understand how to translate in and out from and to C FFI both in Rust and Go. The way a function call from Rust to Go will usually happen is:
- Rust function: We have some Rust code that needs to call the functionality provided by Go. We call the Rust wrapper function that provides access to that functionality.
- Rust Wrapper function: Our Rust wrapper function converts Rust data structures to data structures that can be managed and understood by the C FFI. After conversion, this wrapper will call a C FFI function provided by our static Go library.
- Go Wrapper function: Our Go wrapper function provides an interface for that C FFI function, and this Go function receives the call from previous step. The first thing this wrapper function does is converting the input data to data structures managed by Go and easy to work with in Go, and then starts working with this input data.
- Go function: Our Go function calls whatever Go functions with the input data (in our case, from Trillian) obtaining some data that needs to be returned, and returns this to the Go wrapper function.
- Go Wrapper function: Our Go wrapper code converts these Go output data structures to something that can be returned through the C FFI interface.
- Rust Wrapper function: The output data is received by the Rust wrapper code and is converted into Rusty data structures.
- Rust function: The Rust wrapper code returns to the initial Rust function that uses this output data and goes on with life.
How to actually do this?
If you need to call Go code from Rust, unfortunately there’s not much documentation out there and what you can find is quite scattered along the tubes. Here is a bunch of references that I found useful:
- https://go.dev/blog/cgo
- https://pkg.go.dev/cmd/cgo
- https://pkg.go.dev/unsafe#Slice
- https://belski.me/blog/foreign-function-interface-in-rust-and-go/
- https://doc.rust-lang.org/nomicon/ffi.html
- https://users.rust-lang.org/t/preparing-an-array-of-structs-for-ffi/33411
Since our project includes some other advanced techniques like passing structs from Rust to Go and back, you might also be interested in just taking a look at our bulletin board.
How to actually do this?
This is becoming a bit of a long post, so we will mention a couple of the interesting bits which might not be particularly well documented and I found particularly interesting:
Integrated builds of Go and Rust
One of the most annoying things during this endeavour is the manual work of just building. How do you approach build both? Do you create a distinct package for the Go code? While changing both Go and Rust code, do you always manually first compile the Go code and then build with cargo build?
Our approach was: build Go code automatically, from cargo. You can do this using the build scripts through build.rs.
fn main() {
// Instruct cargo that if these files change, it needs to
// rerun this script
println!("cargo:rerun-if-changed=trillian-board/main.go");
println!("cargo:rerun-if-changed=trillian-board/go.sum");
// Build the go static library
run_command(vec![
"go", "build", "-buildmode=c-archive",
"-o", "libtrillian_board.a", "main.go"
], cwd="./trillian-board/");
// Instruct cargo to statically link to the just-build
// static library `libtrillian_board.a`
println!("cargo:rustc-link-lib=static=trillian_board");
}
Note that this is just some sample Rust pseudo-code. For the real life nitty-gritty details, take a look at our actual build.rs file in sequentech/bulletin-board repository.
Performantly passing big data arrays from Rust to Go
After looking at the 6 steps of calling Go code from Rust, it’s difficult not to have concerns about performance when having so many intermediate steps just to do a simple function call. The real truth is that obviously performance is not as good as just using Rust code, but on the other hand in some cases it’s not as bad as it looks.
When creating new entries, we need to pass the entry data (remember, potentially gigabytes of information) to the Go code. In our current work-in-progress version of the system, we do all that with heap-allocated Rust array.
Following a suggestion in Stack Overflow, we found a way to convert a Rust Array to a C FFI owned array:
fn vec_to_cffi_array<t>(input: Vec<t>) -> (*mut T, usize) {
let boxed_slice: Box = input.into_boxed_slice();
let length = boxed_slice.len();
let fat_ptr: *mut [T] = Box::into_raw(boxed_slice);
let slim_ptr: *mut T = fat_ptr as _;
return (slim_ptr, length);
}</t></t>
Apart from allocating a variable holding the length of the array as part of the returning tuple, there’s no extra memory allocation – we are just dancing with the type system, but in the end we simply convert the Vec<T> into a pointer. The receiver will now be in charge of managing the allocated memory though. More on that later.
BTW we also needed the reverse function (from C FFI Array to rust): also possible with no big memory allocations.
How to use this data array in Go? Well, that turned out to be easy. Just use unsafe.Slice, like we do:
entries := unsafe.Slice(entriesC, numEntries)
This code allows Go access the array as a Slice through the entries variable, indicating to Go that this is memory that the Go Garbage Collector does not need to manage itself. So at this point you need to remember to free the memory to avoid memory leaks. You can do that in Rust side or in Go side. We decided to go the rusty path, using a function like follows:
fn free_vec<t>(ptr: *mut T, len: usize) {
if ptr.is_null() {
eprintln!("free_vec() errored: got NULL ptr!");
::std::process::abort();
}
let entries = unsafe { slice::from_raw_parts_mut(ptr, len) };
drop(unsafe { Box::from_raw(entries) });
}</t>
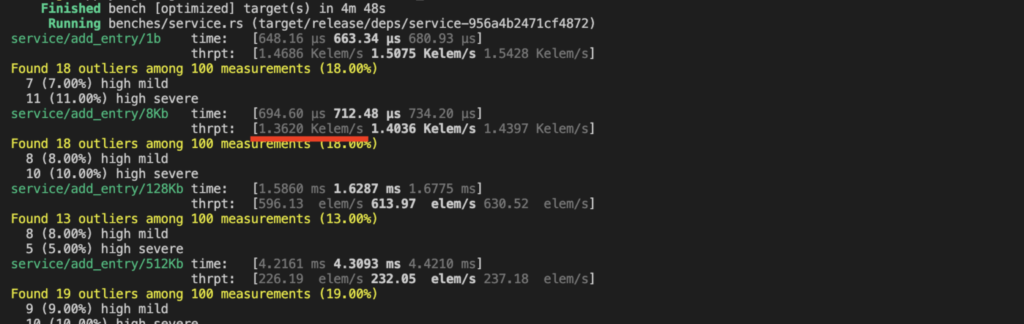
The performance we get is pretty decent when adding entries to this trillian-based log. For small entries, we achieve more than a 1,000 separate inserts per second (sequence+integrate in Trillian terminology). That’s about 2 orders of magnitude more than the ordinary Trillian service that uses MySQL. Without any further optimization. Screenshot from our benchmark:
Stay tuned
There are other interesting insights, techniques and technologies we are using in our 2nd-gen platform that we might want to talk about in the future. For example, about how we generate reproducible builds with Nix or about all the Github Actions we have on every push that include from checking license of dependencies to automatic benchmarking. Stay tuned for more to come.
In the meantime, you can play and tinker around with our work-in-progress and yet-to-be-released open source bulletin board right now, because with one click you can launch a fully working development environment (the exact same one we use) by launching it with Github Codespaces. Isn’t that wonderful? It feels like magic.