In a previous post, we discussed different types of uncertainty due to limited information or computations as the basis for cryptography. A Caesar cipher example demonstrated how an adversary could have all the information to reveal a secret if the relationship between the message space, key space, and ciphertext satisfies the following:

In a previous post, we discussed different types of uncertainty due to limited information or computations as the basis for cryptography. A Caesar cipher example demonstrated how an adversary could have all the information to reveal a secret if the relationship between the message space, key space, and ciphertext satisfies the following:
ZHOO GRQH BRX KDYH IRXQG WKH VHFUHW YGNN FQPG AQW JCXG HQWPF VJG UGETGV
XFMM EPOF ZPV IBWF GPVOE UIF TFDSFU <strong>WELL DONE YOU HAVE FOUND
THE SECRET</strong> VDKK CNMD XNT GZUD ENTMC SGD RDBQDS UCJJ BMLC WMS
FYTC DMSLB RFC QCAPCR TBII ALKB VLR EXSB CLRKA QEB PBZOBQ
Since none of the other attempts yielded meaningful results, we were able to identify the correct message. Since the number of possible keys is so small, only one of them can decrypt a possible message. In technical terms, the key space and message space[2] are small enough compared to the length of the message that only one key will decrypt.
The situation can be coarsely be classified into three cases:
- H(K | C) = H(K) — Perfect secrecy
- H(K | C) < H(K) — Information-theoretic security
- H(K | C) = 0 — Computational security
The epistemic uncertainty mentioned in the previous entry is the epistemic uncertainty of information theory. To illustrate how information-theoretic privacy works, we can use a simple model that reduces computation security when conditions are not met.
Elements of our model
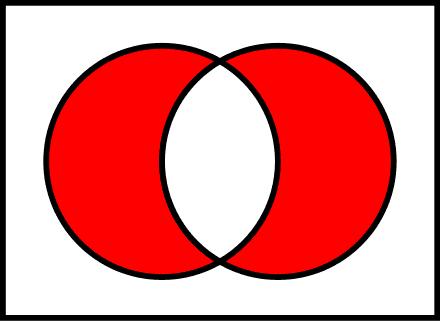
The XOR function
Using a key that determines the exact transformation and allows the intended recipient to recover the secret, our toy model must specify how messages are encrypted from plaintext to ciphertext. We can use a two-character alphabet that consists of binary sequences as messages. As our encryption function, we will use the XOR function, which produces a third binary sequence from two inputs. By choosing this option, we also fix our key space to be binary sequences. Here’s an example encryption:
1010011000 XOR 1100111010 = 110100010
The XOR function produces a ciphertext 110100010 by taking as input a message (1010011000) and a key (1100111010). There is no difference in the process, we can simply imagine that the 1010011000 above is some meaningful content like “WELL DONE YOU FOUND THE SECRET ”. Like in English, in plaintext space (binary sequences) there is a subset of combinations that make meaningful messages, while the rest do not. As a result, we come to the notion of language entropy, which measures how large the meaningful subset of messages is in relation to the entire plaintext space.
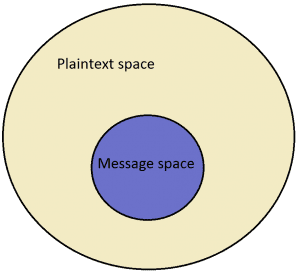
As the language entropy increases, the proportion of the blue region in relation to the entire plaintext space also increases. For binary languages, the entropy ranges from 0 to 1, which is measured in bits per character. Currently, our toy model consists of these components:
- Plaintext space: P ∈ {0, 1}n
- Message space: M ⊂ P
- Key space: K ⊂ {0, 1}n
- Ciphertext space: C ∈ {0, 1}n
- Encryption function: XOR: P x K → C
- Language entropy: HL ∈ {0.0-1.0}
The security characteristics of our system are contingent upon three parameters that are associated with the aforementioned factors:
- n:the number of characters in the plaintext
- |K|: the size of the key space
- HL: the language entropy
- RL = 1 — HL: the language redundancy
The final parameter, redundancy, is essentially a rephrasing of the language entropy. The equation that formulates the security in relation to these parameters is:
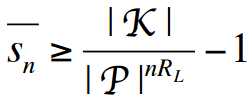
The given equation provides a minimum estimate for the anticipated quantity of false keys, denoted by the term “sn”. A false key, for a specific ciphertext, is a key that decrypts the ciphertext into a message that is not equivalent to the message that was initially encrypted using the correct key. As illustrated in the initial encryption example mentioned in the post, it was observed that among all the attempted keys used to decrypt the ciphertext, only one produced a coherent plaintext, implying that the ciphertext had no false keys. Conversely, if one of the keys, denoted as “s”, had decrypted the ciphertext into something similar to
THE MESSAGE COULD BE THIS
then in such a scenario, the key “s” would be considered a false key. If an attacker were to attempt all possible keys, they would end up with two potential messages, making it challenging to determine the accurate one. As a result, the confidentiality of the secret would be relatively preserved. The presence and quantity of anticipated false keys determine the category to which a cryptosystem belongs among the three general classifications mentioned earlier. Examining the false key equation reveals the following patterns:
- sn increases with the size of the key space, |K|
- sn decreases with the size of the plaintext, n
- sn decreases with language redundancy, RL
A visual representation

Encryption representation with n = 2, H = 0.8, M = 3, K = 1
The image’s left side depicts a visual representation of our parameter values for the toy model, where the left axis denotes the plaintext space, and the right axis represents the ciphertext space. Each point on the graph symbolizes an encryption or a mapping from the plaintext space to the ciphertext space. To obtain the visual representation, we set n = 2, resulting in a plaintext space with four elements. Out of these four, three convey meaningful messages, considering a language entropy of 0.8. Thus, the three red dots on the graph correspond to the three encryptions of these three meaningful messages. Since K=1, each plaintext has only one corresponding ciphertext or, visually, only one point on any given horizontal line. For comparison, see:

n = 2, H = 0.8, M = 3, K = 3
Displayed in the image are nine points that correspond to three messages encrypted using three distinct keys. Consequently, each horizontal line on the graph signifies all the encryptions for a specific message under various keys. As for the variance in color, consider the following alternative set of parameters:
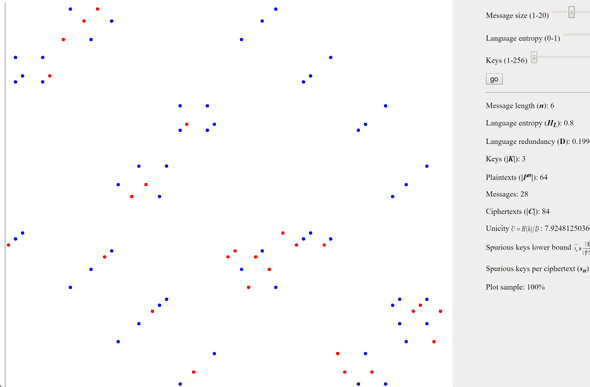
n = 6, H = 0.8, M = 28, K = 3
If we increase the plaintext length, the number of meaningful messages also increases to 28, resulting in a total of 28 x 3 = 84 encryptions, represented by red and blue points in this particular case. Can you discern the pattern that explains this phenomenon? It may be challenging to identify, but the explanation lies in comprehending the significance of vertical lines in the visual representation. Points that lie on the same horizontal line denote distinct encryptions for the same message, whereas points that are positioned on the same vertical line signify different messages encrypted using the same key. As previously observed, this is precisely the situation where an attacker cannot deduce the secret by attempting all possible keys in reverse, as it is impossible to distinguish the original message among the resulting messages.
Ciphertexts represented by blue points have more than one key that can decrypt them into a meaningful message. Alternatively, blue points signify ciphertexts that possess one or more spurious keys.
sn > 0 ⇒ blue point
sn = 0 ⇒ red point
We can now visualize the properties of information-theoretic security that we mentioned earlier.
- sn increases with the size of the key space, |K|
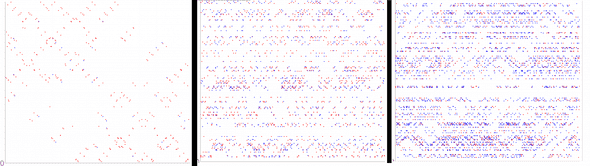
Fixed n, H, increasing values of K
In terms of visualization, the number of red dots proportionally increases.
- sn decreases with language redundancy, RL
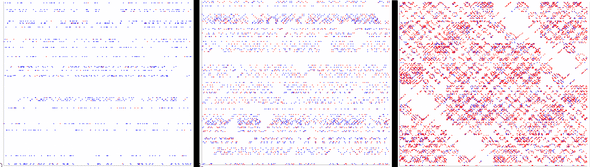
Fixed K, H, increasing values of n
In terms of visualization, the number of red dots proportionally increases.

Fixed n, K, decreasing values of H (increasing values of R)
Visualizing the categories
In addition to these patterns, we also discussed three general categories that cryptosystems fall into:
- H(K | C) = H(K) — Perfect secrecy

n = 8, H = 0.55, K = 256
In terms of visualization, the number of blue dots per column is equivalent to the number of horizontal lines. This indicates that the adversary cannot extract any information from the ciphertext. It is noteworthy that 2^8 = 256, which corresponds to the value of K.
- H(K | C) < H(K) — Information-theoretic security
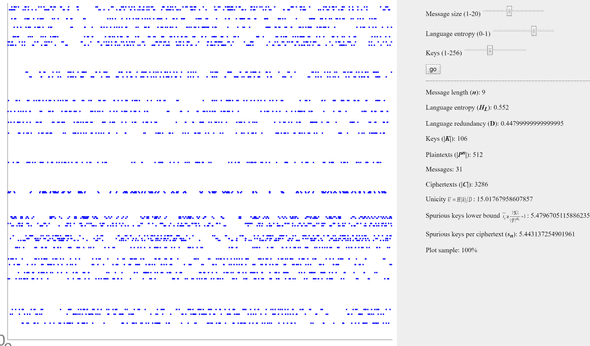
n = 9, H = 0.55, K = 106
In terms of visualization, only blue dots are present. Each ciphertext is partially secured, implying that the attacker lacks sufficient information to disclose the secret definitively.
- H(K | C) = 0 — Computational security

n = 13, H = 0.53, K = 29
In terms of visualization, there are red dots indicating ciphertexts that do not have information-theoretic protection and rely on computational security for their confidentiality.
Try it yourself.
This post discusses the main concepts presented in Claude Shannon’s Communication Theory of Secrecy Systems published in 1949. Additionally, we have created a toy model to help visualize the security properties of cryptosystems and how they change with the primary parameters. If you’re interested, you can experiment with the model here. If you’re a teacher and find it useful, please inform us!